有足够的个性化差异的可交互产品/游戏,是 AI Coding 可能的出圈点。比如,以个人形象为主角的、融入了自身经历的小游戏;比如,一个可以在里面不断做个性化扩建的自由世界,像“我的世界”。如果有这些新的形态,就会催生一个新的内容平台去承接这一类产品。
AI 视频
AI 视频的产物应用涵盖太广,难以细拆,但近期也看到一些大众化和新形态的可能性:
日常表达:AI 视频是想象力的相机。我们的日常表达,一部分通过摄像头记录和分享,另一部分心情的传达,比较难通过摄像头,在以前更多通过文字,以后可能更多通过 AI 这个想象力的相机。它能把你本来只能用文字描述的心情和感想,转成更容易引起共鸣的画面。近期在抖音上火了一阵的 像素风 AI 视频,就是这种感觉。(印象较深的是,勇士队输掉季后赛的那天,看到了一个像素风视频很好表达了郁闷/不甘的心情,很有共鸣,这种心情用真实的图片视频和文字都很难表达)
可交互视频:最近看到 odyssey 发布了可交互视频,40ms 生成一帧,根据用户行动实时生成下一帧,体验上像玩游戏一样。可交互视频可能是 AI 视频生成新形态的关键,它不一定是非常实时的交互,比如看一个剧,可以自己修改剧情走向,看到视频里的一个场景,可以进去这个场景无限扩充看它整个空间,都是可能的场景。
日常心情表达是 AI 视频很能大众化的场景,消费价值和消费频次高,但催生不了新平台,生成的视频都会回到原来的内容/社交平台上。可交互视频这种衍生的形态,才会需要一个新的平台去承接。
新形态的核心:交互
看下来无论是 AI Coding 还是 AI 视频,交互 都是新内容形态的关键点。
因为这波 AI 浪潮是生成式 AI,生成的产物都是业界已有的形态,如果只看生成的产物,在没有新的硬件设备、使用环境等其他变量的情况下,只会有生产效率的提升,很难诞生新的内容形态和平台。
生成式 AI 真正独特的地方,是生成的过程。需要用户频繁通过生成产生交互的场景,才会是新的内容场景,才能产生新的内容形态。
AI Coding 和 AI 视频都有在各自领域里通过交互产生新的内容形态的可能。另一种可能是,这两者做进一步的结合,逻辑+画面都实时生成,不断创造的可玩的虚拟世界,可能又能回到元宇宙的概念。
计算机的核心从 CPU 转向 GPU,上个时代依靠程序员写代码指挥 CPU 执行指令解决问题,构成了现在庞大的 IT 产业,程序员是中心。现在的时代逐渐转变,GPU 生产的 token 逐渐能解决越来越多的问题,能思考,能生成代码指挥 CPU 去执行解决问题,计算的核心一定会转向 GPU,世界对 GPU 的需求只会越来越高。
给 AI 分了四个阶段,Perception AI → Generative AI → Agentic AI → Physical AI,不是很认同,Agentic 和 Physical 都是 Generative AI 的延续,不过无所谓,可以看到 Agentic 这个概念实在是火爆。
Scaling Law 没有停止,Agentic AI 需要深度思考,深度思考有新的 Test-time Scaling Law,越多的 token 输出效果越好需,要多轮理解和工具调用对 token 的消耗更是指数级上涨。
Physical AI 要更好地理解现实世界,声音/视觉/触感,都会比纯文本思考对 token 消耗的诉求更高,像 2G 时代看文字新闻,3G 4G 图片,5G 视频一样。
多个 session 都在推广 NVidia 的 Video Search and Summarization Agent,串联从视频的获取→分割→VLM识别、CV物体识别和跟踪→数据处理存储和RAG召回→用户对话 整个流程,做到可以对视频提供实时分析和报警,也可以自然语言交互查询视频内容,边缘部署,适合用于监控,算是用 NVidia 技术栈做 AI 应用的一个标杆范例。
AIGC
关注了下视频 AIGC 相关的几个 Session
在好莱坞干了几十年的视觉效果的 Ed Ulbrich 开了个公司 Metaphysic,以前的电影特效制作成本巨大,对人的处理还很难跨过恐怖谷,而基于 AI 技术做特效,用完全不同的技术栈,效果好成本低,是一种颠覆。metaphysic 给娱乐行业提供人脸替换、数字人的服务,看起来是用的 GAN,在人物换脸技术上,GAN 还是更能做到稳定和实时,特别是实时这个点,基于 diffusion 很难做到。基于市场需求,利用已有的不同技术(甚至是上一代技术)深入解决问题,是有空间的。
但模型本身目前解决不了所有问题,还需要工程上的一些策略和串联做优化。例如 Tree of Thought 让任务不是以线性一步步执行的形式,而是生成解决问题的多个节点,多角度思考问题,形成树结构的任务,评估节点的价值,在里面寻找最优解。 Reflexion 会有 Evaluator 对各种反馈(工具调用结果/模型输出/用户指令)进行反思,梳理改进方向,也会把反思结果作为知识库经验,指导后续的任务。
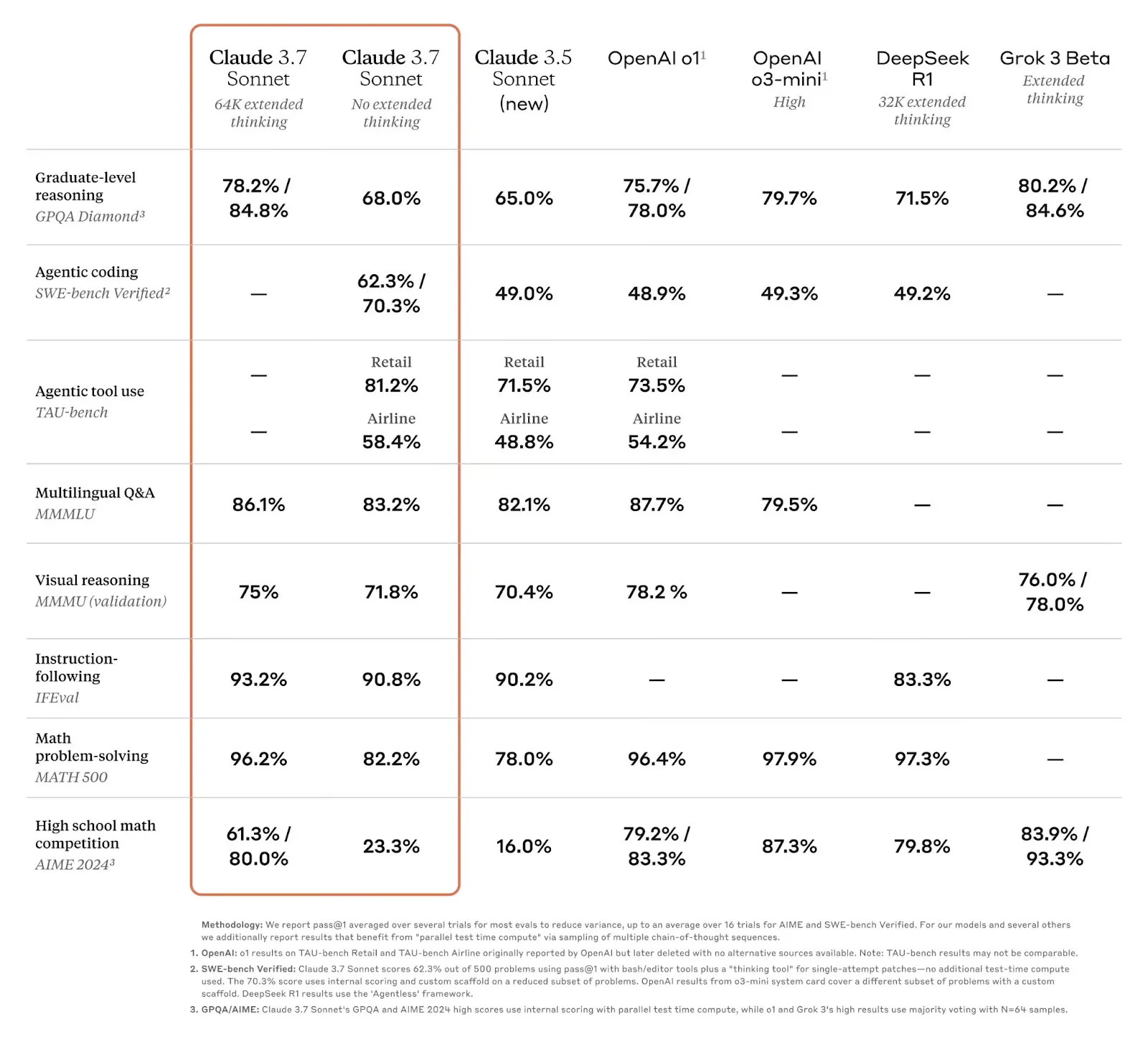
Claude 3.7 Sonnet 在万众期待中推出了,为什么期待,因为从 Claude 3.5 Sonnet 发布后,一直是AI Coding Agent 领域最好的模型,综合效果没有对手,后面陆续推出的 o1/o3/DeepSeek 都没能撼动,更让人期待 Claude 3.7 Sonnet 在 AI Coding 领域能不能有进一步提升。
Claude 3.7 放出来的 Benchmark 里,有两个是跟 AI Coding Agent 表现强相关的: