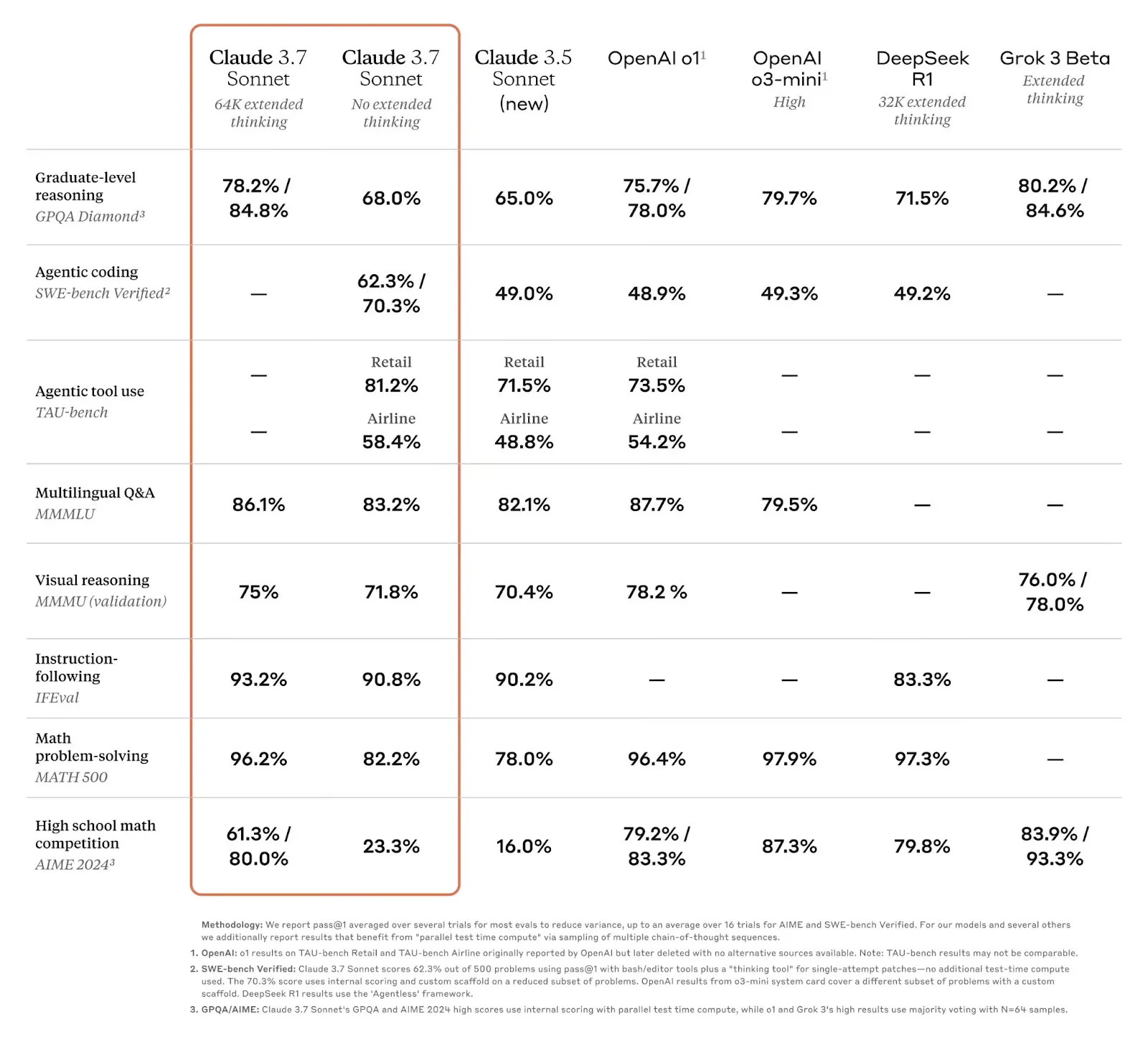
在 Agent 使用的模型上,Claude 一直独一档,Deepseek、豆包、Gemini 等模型跟它都有很大差距,很多号称 benchmark 接近和超过 Claude 的实际效果都不行。
K2 出来后在 Agent / Coding 相关的 benchmark 上效果很不错,同时也在一些 Agent 场景上试了下,实际体验是不错的,值得学习下它是怎么做的。
它的技术论文《KIMI K2: OPEN AGENTIC INTELLIGENCE》公开了模型训练过程的一些信息,一起学习下。

概览
K2 几个重点:
- MuonClip 优化器,支持了万亿参数级别的模型预训练能稳定进行。
- 大规模构造 agent 合成数据。
- 通用的强化学习框架,不仅适用于对有明确对错的任务(数学/逻辑/代码开发等),也适用于开放型任务(写作、多轮对话等)。
分别对应大模型训练三部曲:预训练,SFT,强化学习。论文分别阐述了这三个阶段做了什么。
预训练
这部分介绍了训练 K2 基础模型的架构设计、优化器创新、数据增强处理,以及训练的硬件配置和调度。
架构
模型架构遵循 DeepSeek V3 的架构,只是调整了一些关键参数,1.04万亿(1000B) 参数量的 MoE 模型,激活参数32B。
MoE(Mixture of Experts) 架构能做到高性能低成本,基本要成为 LLM 标配。 模型参数量越大,模型在训练过程中能存储的信息量就越多,模型聪明程度越高,这是 scaling law。但参数量越大,使用模型的推理成本就越高。 MoE 架构可以设计参数量很大的模型,但在推理时,每一个 token 都会被路由到到其中几个子模块(称为专家)去处理,只有少量参数参与了计算。 这也是为什么之前 DeepSeek 的成本很低的原因之一。K2 1000B 的参数量级,激活参数 32B,相当于它的推理成本跟 32B 大小的模型差不多。
跟 DeepSeek V3 的差异是调整了一些关键参数,比较细节了,特别提到两个点:
- 高稀疏性(MoE 专家数量多但激活很少)的设计能在同样计算量下让模型表现更好,但专家数量多有成本,K2 选了一个性价比高的稀疏性数值来平衡效果和成本。384个专家激活8个。
- 注意力头 (attention heads,可理解为对输入向量的拆分) 多了对效果提升有限,反而在处理长文本时会慢,不划算。把注意力头从128降到64。
模型架构做的事不多。
MuonClip 优化器
预训练阶段 K2 最大的创新点在 MuonClip 优化器,花了较大篇幅介绍。简单从基础概念出发理解下它做了什么:
- 优化器:模型训练过程中会不断调节参数,优化器会决定如何去调整这些参数,让模型能更快、更稳定地收敛到一个较好的状态
- Muon:是一种优化器,算法原理还挺复杂不展开,简单说它的作用能在保证一定准确度前提下提升训练速度,能比常用的 AdamW 优化器更快地完成训练任务。
- MuonClip:Muon 虽然训练速度快,但容易不稳定,理解为可能会一下把模型参数调整得太猛,无法收敛回来,训练崩溃。越大的模型会越容易出现这个问题,K2 万亿参数下更是容易。MuonClip 解决这个问题,简单理解是在 Muon 基础上增加了一个叫 QK – Clip 的裁剪器,超出阈值时做好调节,避免训练的大幅波动。
数据处理
预训练中有个 token 效率的概念,每个 token 对模型更新的影响越大,token效率越高,数据处理目标提高 token 效率,其实就是提高数据质量。
K2 有 1.5 万亿 token 的数据去训练,极端假设这1.5万亿 token 都是一样的,那模型什么也学不到,token 效率很低,如果 1.5 万亿 token 均匀包含了每个领域多样性的数据,token 效率就高。
K2 做了几个事提升 token 效率:
- 对知识领域的数据,用 LLM 以不同的风格和视角重新生成一份数据(可以理解为蒸馏了某个 LLM 的文风?),还细化了重写方法:分块重写每一段最后拼接在一起,以及有检测模型确保重写内容与原始内容一致。
- 对数学数据进行重写,遵循 SwallowMath 数据集里的方法,包括去掉题干冗余描述、补全上下文、繁琐的解答重写为简洁连贯分布逻辑、确保格式统一。
互联网数据已经用完的情况下,如何在这些数据里清洗重组出多样和高质量的数据,提升预训练效果,是持续可以做的事。
SFT
除了常规的高质量标注数据做 SFT,K2 专门针对 Agent 场景创建了一套合成数据的流程,能造出大量高质量的 Agent 对话轨迹数据(trajectory),对预训练模型进行 SFT,让模型学会 agent 任务规划/调用工具/环境反馈相关的套路/格式/规则。
这个流程分三步:
1. 造工具(Tool spec generation)
- 从github 爬3000+个 MCP 工具,作为数据集之一
- 选一些关键类别(比如金融交易、软件应用、机器控制),每个类别演化出多个应用领域(比如股票交易、开发者工具、工业机器人)。
- 为每个领域创造一些新的工具:用 LLM,基于上面 MCP 工具的定义和规范,创造出工具的接口、描述、操作语义,确保各个类别和领域数据的多样性。例如下面这样的工具,一共造 20000 多个:
{
//仅示例,非实际定义的格式
name: "financial_db_search",
description: "查询金融数据库中的产品信息,支持股票、债券、基金的基本数据(如代码、名称、价格、发行量)及历史交易数据(如近30天收盘价)",
// 输入参数的JSON Schema定义(约束模型传入的参数格式)
properties: {
type: "object",
required: ["product_code"], // 必选参数
properties: {
product_code: {
type: "string",
description: "产品代码,如股票代码(A股:600000.SH,美股:AAPL)、债券代码(019547.IB)"
},
time_range: {
type: "string",
enum: ["latest", "30d", "90d", "1y"],
default: "latest",
description: "查询时间范围:最新数据(latest)、近30天(30d)、近90天(90d)、近1年(1y),默认返回最新数据"
},
}
}
}
2. 造 Agent 任务(Agent and task generation)
- 合成各种系统提示词,从上面两三万个工具库中配备不同的工具组合,生成几千个 Agent。(system prompt + tool set = Agent 定义,这里怎样去做工具配备没详说,应该是由 LLM 加一些流程完成。)
- 基于每个 Agent,生成简单到复杂的各类任务,每个任务都配有明确的评分标准,规定了任务成功指标、预期的工具使用和中间的检查点。
3. 造对话轨迹(Trajectory generation)
- LLM生成具有不同沟通风格和偏好的用户角色,跟上述 Agent 进行多轮对话。
- 对话过程中,Agent 会调用工具,但上述生成的工具只有 spec (接口定义/描述),并没有真正的实现,所以做了一个工具执行模拟器,用 LLM 模拟调用了这个工具给出结果返回过去。
- 也有部分工具不是调工具模拟器,会针对比如软件编码任务,给一个真实的调用环境,真实地执行实际工具调用代码,返回数据。
- 会有裁判 LLM 去评估这里生成的对话记录的质量,符合要求的才会挑出来作为训练数据。
最终造出的数据示例:
//仅示例,非实际定义的格式
<|system|>
你是金融股票专家,可调用工具:stock_quote(查实时行情)、industry_trend(查行业趋势)
[{
name: "stock_quote",
description: "查询金融数据库中的实时行情",
properties: {
product_code: {
type: "string",
description: "股票代码..."
},
}
}, { ... industry_trend}]
<|/system|>
<|user|>帮我看看宁德时代(300750)现在的股价和涨跌幅。<|/user|>
<|assistant|>需要查询宁德时代的实时行情。<|tool_call|>{"name":"stock_quote","parameters":{"code":"300750","fields":["price","change"]}}<|/tool_call|><|/assistant|>
<|tool_response|>{"code":"300750","name":"宁德时代","price":118.50,"change":"+2.3%","time":"09:45"}<|/tool_response|>
<|assistant|>宁德时代(300750)当前股价118.50元,涨2.3%(截至09:45)。<|/assistant|>
<|user|>那新能源板块这周表现怎么样?适合加仓吗?<|/user|>
<|assistant|>用户想了解新能源板块周趋势,需调用行业工具。<|tool_call|>{"name":"industry_trend","parameters":{"sector":"新能源","period":"week"}}<|/tool_call|><|/assistant|>
<|tool_response|>{"sector":"新能源","period":"week","trend":"上涨5.2%","hotspots":"储能/充电桩","risk":"政策不确定性"}<|/tool_response|>
<|assistant|>新能源板块本周上涨5.2%,储能和充电桩领涨,但需注意政策不确定性。短期可少量加仓,建议持仓不超过总资金的15%。<|/assistant|>
总的来说,通过少部分真数据和大部分合成数据,去造出大量模拟 Agent 对话轨迹的高质量数据,数据量原文说是数以万计,也可能不止。这些数据可以直接用于 SFT,让模型学会 Agent 需要的多轮交互推理、工具调用能力。
这里造数据用到的 LLM,猜测是 claude sonnet 4,算是蒸馏了 claude 的 agent 能力?
强化学习
强化学习阶段讲了很多策略,核心是通用的给训练环境、造任务、定义奖励模型。对于可验证奖励的任务,有多种不同验证策略,创造和引入大量的任务做训练;对于不好验证奖励的任务,用自我评判的方式去选更好的输出;另外也介绍了算法上的几个小优化策略。
可验证奖励任务
给模型的强化学习搭建了一个训练场(Gym),设计了各种有明确对错标准的任务,让模型在里面学习。
- 数学题、理科推理题:收集大量数学、科学、逻辑题,也包括数独、密码破译等逻辑题,补全冷门的领域的题目(这个好像比较常规?)。清洗数据,用模型筛掉太难和太简单的,留难度适中的题目,模型练了能进步。
- 听懂复杂指令:
- 对一些可验证输出的 prompt case,LLM 生成结果检测的代码去做检测。比如“生成小故事,别太长”,LLM 生成一个检查结果字数的函数,超过200字就扣分。
- K2 数据团队自己造了一波复杂的 prompt 和这波 promot 的评判规则数据。
- 参考 AutoIF 指令扩充,输入一小批人工指令,用 LLM 自动生成更多变体,形成丰富复杂和可验证的指令集。例如指令“7加9加8等于多少”,扩写成“计算把7加到9上,再加上8,等于多少”之类的形式,并生成 python 代码去测试输出的答案是否正确。
- 说真话:参考 FACTS Grounding 的做法,训练了一个忠实度判定模型,能识别每个句子对事实的遵循度,作为奖励模型之一。比如模型说参考表1 数据X,实际上表1并没有数据X,就扣分。
- 编程和软件工程能力:编程上包含各种竞赛题目,额外给这些题目找了对应的单元测试。软件开发方面,跟 SWE-bench 的做法一样,扒了 github 上大量的代码修复 case,issue 描述扔给模型生成修复代码,搭建了环境支持运行代码单源测试,测试结果作为奖励模型。
- 安全:收集一堆危险问题(暴力/色情等)让模型学会拒绝回答。用一个 LLM 模拟生成一些绕过安全规则的问题(比如扮演角色/讨论正经问题过程中混入危险问题),让 K2 回答,再用另一个 LLM 去判断 K2 的回答是否危险,做好引导。
总的来说,就是各种造数据,定义奖励模型,让模型靠近我们想要的结果。
自我评判机制
上面基本是能定义好奖励模型的任务,接下来是对不太好衡量结果的任务怎么进一步提升,例如回答有没有帮助、有没有创意、推理深度够不够等。
这种要不就是人类标注数据,要不就是用 LLM 评估结果。K2 这里大致的意思:
这里大意是让 K2 自己对自己的输出好坏进行评判:
- 在预训练和 SFT 阶段,给 K2 喂相关的人类标注能用于评判好坏的数据,让模型初步有评估好坏的能力。
- 强化学习阶段,给 K2 输入我们的偏好(system prompt),包括核心价值(例如表达要简洁、逻辑要连贯、保持客观等)和规范(例如不要在开头迎合用户赞美),让它去评判自己输出的内容符不符合我们偏好。
- K2 的评判能力会在训练过程中也不断提升,因为同时会拿它去评判之前提到的那些可验证结果的问题,它如果评判错了也会纠正参数去提升评判能力。
算法策略
介绍了几个算法上的小策略:
预算控制:RL 只看最终结果是否能得到奖励,所以模型会倾向于输出更多的内容,更多的内容意味着更高命中答案的概率,但对很多任务来说是没必要的。K2 对不同任务类型设了输出 token 限制,超出会惩罚,引导模型输出简洁有效的回答。
PTX loss(Pre‑Training Cross‑Entropy) :OpenAI 在 RLHF 提出的,RL 过程中避免模型对原先能力的遗忘,K2 准备了一份高质量数据,训练过程会时不时加入评估,如果模型对这些数据效果变差了,就惩罚,让学习更稳健。
温度衰减(Temperature Decay):温度在大语言模型里是指激进输出还是保守输出,更细的理解是 next token 推理时是直接选概率最高的(保守),还是随机选前面几个(激进多样)。温度衰减是训练前期先激进多尝试不同方向,后期保守收敛,保持输出稳定。
其他
强化学习相关就这些,对 Agent 推理能力起作用的,是可验证奖励模型里的 2-让模型理解复杂指令和 3-输出遵循事实,以及自我评判机制让模型输出推理深度更好。对 Coding 能力起作用的,基本就是编程和软件工程能力。
这些方法应该都多少在各种论文上出现过,但能不能做得好,数据质量怎样,中间有多少细微的策略调整,就看细活了。
整个模型训练基本就这样,其他的内容就剩下各种 benchmark 评估了,不再列。
感受
看完什么感受?
- 整个论文工程同学是能看懂大概的,算法公式比较少,我理解主要是大模型算法结构已经固定,让实用性大模型训练更偏向是一个系统优化工程,而不是创新算法项目。
- 感觉友商看了这论文也没法快速复刻,因为用的很多方法似乎多少有在各种论文上出现过,小部分是特别的算法策略,影响模型效果的应该在每一个策略和数据构造处理的细活上。也许某一个策略和数据是对模型效果影响很大,但论文没提到。
- K2 很厉害,值得敬佩,它目的也是造一个 Agent / Coding 能力好的实用性模型,策略做法都很强。只是感觉只靠这些策略模型没法突破上限,scaling law 没有继续突破,thinking 模式的 test time scaling 被抛弃,最近模型惊艳的进展基本来自于多模态模型,纯文本 LLM 下一个突破不知在哪里,等 OpenAI 了。